


LLM pruning and distillation

In my last post, I referenced Dave Friedman’s analysis of the Aschenbrenner manifesto highlighting research challenges in data efficiency improvements — how to use less data for equivalent training. NVIDIA researchers recently published a paper on “compressing the Llama 3.1 8B and Mistral NeMo 12B models to 4B and 8B parameters, respectively, using pruning and distillation” (following another paper I found on Twitter). I’ll read these now:
Compact Language Models via Pruning and Knowledge Distillation, Sreenivas & Muralidharan, et al. (2024)
Both of these papers highlight the high cost model providers (Meta) take on by training model families (Llama) from scratch, so I did a quick Google search to determine the order of magnitude dollar value as a sanity check. Reddit’s not always the most reputable source, but this one seemed reasonable:
Llama 3: That's 24,000 x $30,000 (estimated) = $720 million in GPU hardware alone. Of course, this doesn't include other costs like extra hardware and personnel costs etc. I'm guessing the total costs may have exceeded $1 billion. — Reddit
So the authors ask:
can we train one big model, and obtain smaller, more accurate (w.r.t. training from scratch) models from it through a combination of weight pruning and retraining, while only using a small fraction of the original training data?
Weight pruning
The authors reference a good survey paper of LLM model compression methods (IEEE) and a paper from a few years ago on sparsity in deep learning (ETH Zurich). Generally, pruning removes “unimportant components” (neurons, layers, etc.) in a “pre-designed” model, reducing memory usage and cost, but isn’t totally effective on its own for LLMs:
Although pruning has shown remarkable results in CNNs [97], its effectiveness is less robust for LLMs when compared to other compression techniques such as quantization and distillation. The reason why pruning becomes less effective comes from the fine-tuning process. The high cost of fine-tuning due to the large number of model parameters makes it more difficult to achieve the full effect of pruning. Nevertheless, pruning is a crucial technique for compressing models, necessitating further exploration to enhance and refine its effectiveness in yielding improved results in LLMs.
In unstructured pruning, pruning units focus on individual weights (weights to be pruned out are zeroed out) — because this is not constrained by network structure (as with structured pruning), this can lead to higher sparsity ratio, but trades off inference speed (due to “non-systematically occurring zero values”). Pruning metrics underlying the pruning methods include magnitude (absolute value) based (intuitive importance of weight), loss-based (minimizing impact of removing a pruning unit); I find during-training (trains and prunes dense network in tandem) interesting. Upstream & downstream pruning simply refer to the order of pruning vs. fine-tuning: upstream means pruning before fine-tuning, and downstream means fine-tuning the pruned model.
Sparsity
As ETH Zurich researchers highlight in their paper, sparsity and sparsification is useful in improving generalization and robustness, and improving inference performance.
Generalization is “how well the model performs for unseen data drawn from the same distribution as the training data but was not used for training”. Sparsification follows Occam’s hill where, as we start to sparsify, accuracy increases because we aren’t learning as much noise, and performance as well as a sparser model forces a “stronger regularizer”. Performance plateaus as sparsity increases, until we hit a breaking point where accuracy drops off significantly as the model becomes too crude.
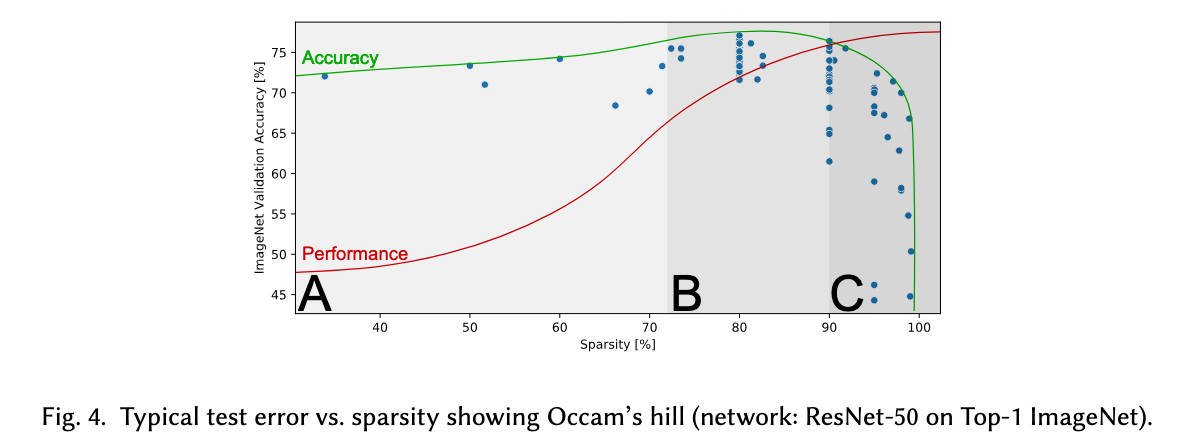
Hence sparsification is a useful technique to improve performance, but as with any optimization technique comes with caveats. The authors of this sparsity paper highlight static (prune once before training, then don’t update the model during training at all) vs. dynamic (prune and add elements during training) sparsity. Finally, “many works have shown that retraining immediately following each pruning step and fine-tuning after the last pruning step are both crucial for well-performing sparsification schedules.”
Knowledge Distillation (KD)
KD is transferring knowledge from a larger / more complex (teacher) model to a smaller / simpler (student) model. The student mimics the output and/or intermediate states of the teacher, but as with human students and teachers, it’s not an exact copy of knowledge. For LLMs, black-box distillation methods include instruction-following, chain-of-thought, and in-context learning:
Due to the fact that black-box distillation can only transfer knowledge through datasets, it necessitates a sufficiently comprehensive dataset. Therefore, the common effort in [instruction-following] involves constructing a large dataset (comprising instructions, inputs, and outputs) to enable the student models to learn as much as possible from the teacher models.
Fascinatingly, “SELF-INSTRUCT employs a self-distillation approach, where the model serves both as the teacher and the student.”
Chain-of-thought: “the ability of a large language model to provide better answers to questions based on the rationale within the given prompts. The typical paradigm of CoT distillation utilizes large models to generate reinforced datasets containing rationales, which are then used to fine-tune the student model.”
In-context learning: “capacity of large models to generate correct outputs for new inputs based on some input-label examples without updating model parameters.”
Back to the NVIDIA paper:
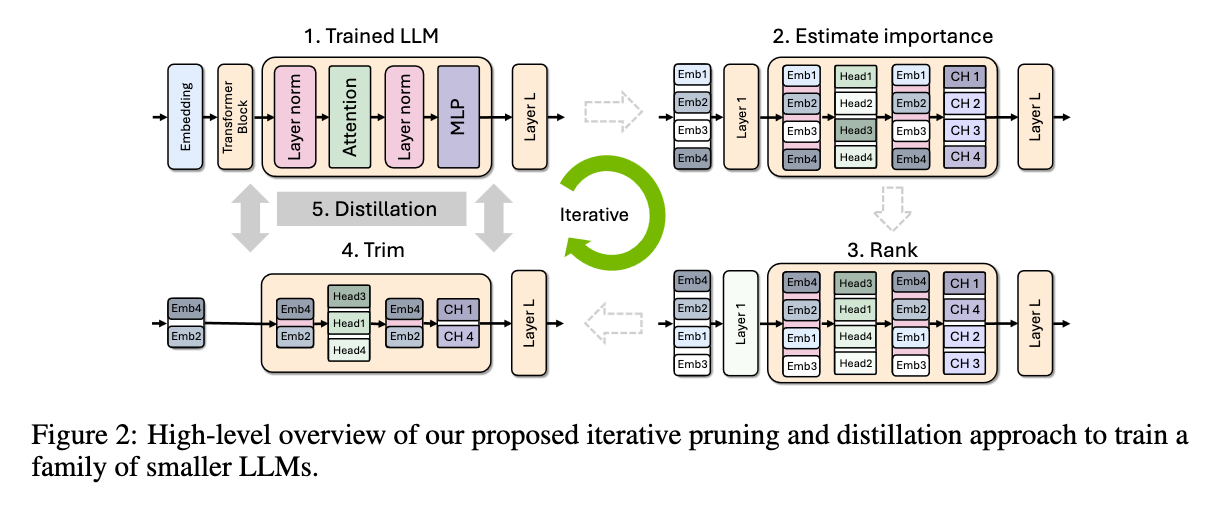
The authors propose a purely activation-based importance estimation strategy, specifically compute activation-based importance scores for (attention) heads, neurons, and embedding channels:
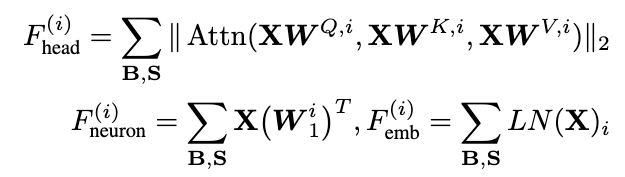
The last axis making this a comprehensive estimation strategy is depth. They estimate layer importance via perplexity (impact to perplexity of removing the layer) and block importance score (estimate of layer sensitivity), which is faster to compute than perplexity as a metric because it is mathematically designed to be computable in a single forward pass:
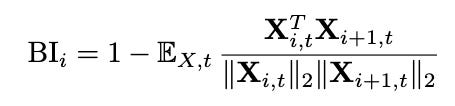
Finally, their strategy is iteratively alternating between pruning and importance estimation for a given axis (or combination of axes) — iterative importance.
They search for optimal architectures given a search space and parameter budget, perform lightweight (~1.8 parameters) retraining on feasible candidates, and perform full retraining on the best candidates.
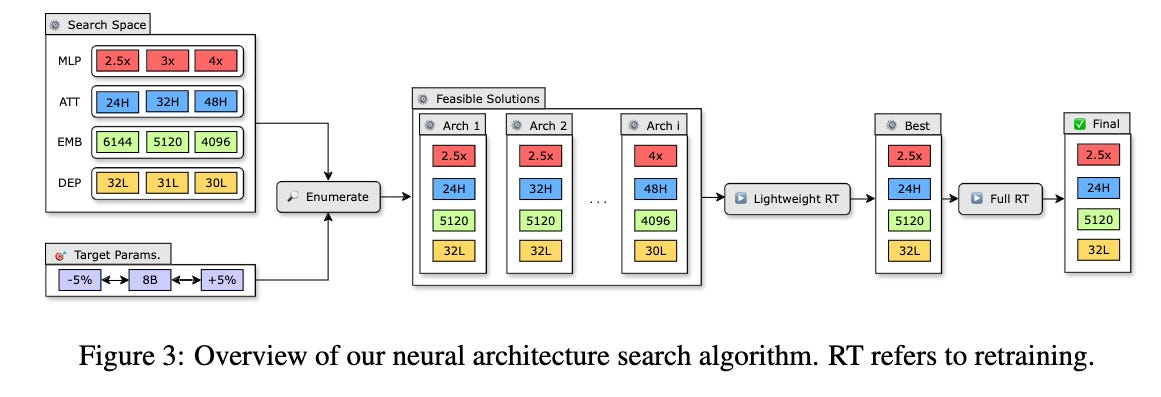
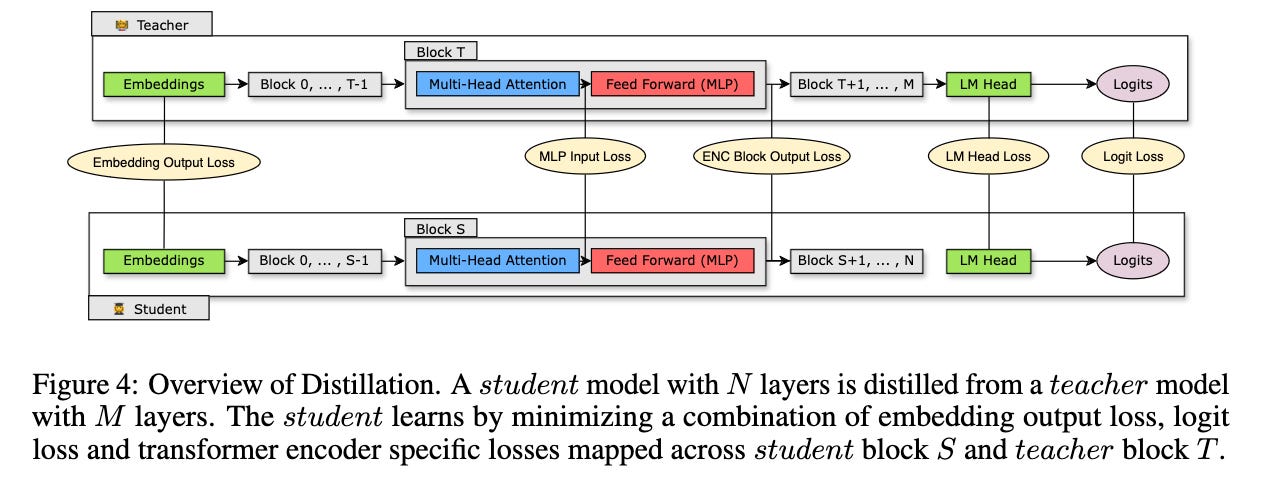
They explore retraining with conventional KD (ground truth labels) as well as KD using supervision from the unpruned teacher model.
They are able to compress Nemotron-4 15B to 8B and 4B parameters (Minitron). Overall, they are able to achieve 1.8x cost saving (based on FLOP count) with approximately similar model performance, with some possible areas of improvement in coding tasks, and highlight best practices learned during this work.
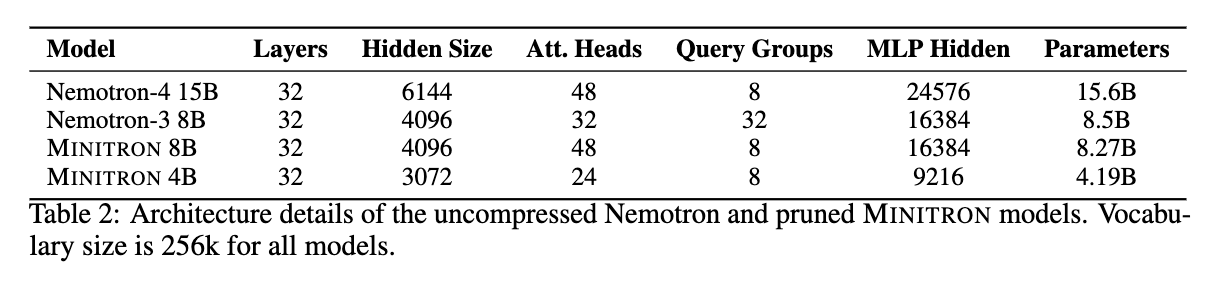
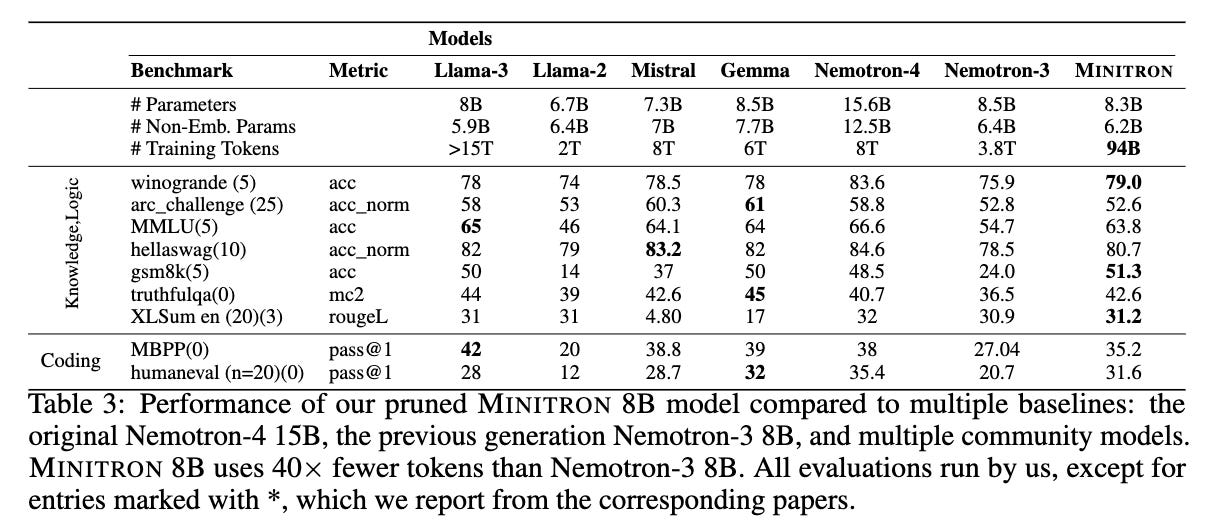
LLM Pruning and Distillation in Practice: The Minitron Approach, Sreenivas & Muralidharan, et al. (2024)
We got through a lot of the technical foundation while reading the last paper, so I’ll devote this section to going over the updates.
They’ve done it again, and on external models now, compressing Llama 3.1 8B down to 4B, and Mistral NeMo 12B to 8B. This requires a critical change to the teacher-student learning model:
While following the original paper, we make a key modification: due to lack of access to the original training data, we fine-tune the teacher model on our own dataset before pruning and distillation. We refer to this step as teacher correction.
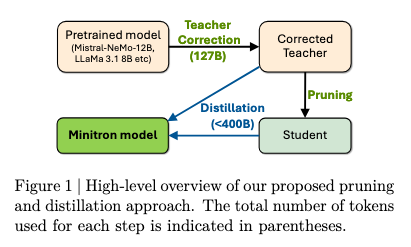
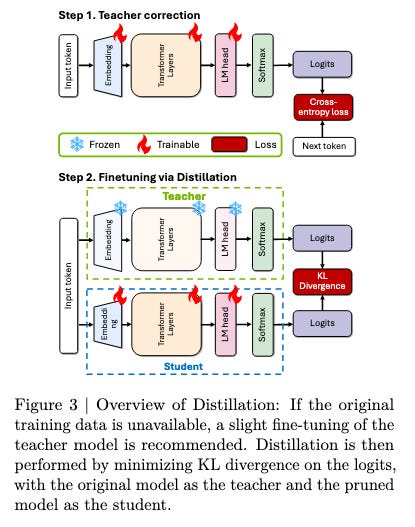
Teacher correction doesn’t affect the optimality of pruning and can even be performed in parallel with distillation.
Let’s be very clear: NVIDIA was able to fine-tune SOTA teacher models on their own dataset (since they naturally don’t have access to Meta’s or Mistral’s original datasets) and achieve reasonably benchmark-matched, 1.5-2x compressed models of both, even outperforming Mistral NeMo 12B on HumanEval (programming problems). The compressed model is worse off with Llama 3.1, but also recall the hundreds of millions of dollars of potential cost savings here for a full training.
What I’m reading next
Nexus: Specialization meets Adaptability for Efficiently Training Mixture of Experts (Gritsch et al., 2024)
Introduction to Mechanistic Interpretability, Sarah Hastings-Woodhouse