


ML recap, August 2024

Anant sent me a few interesting reads this month that I’ve had on my to-do list to read critically (thanks again Anant!):
AI models collapse when trained on recursively generated data (Shumailov et al., 2024)
Model collapse is a degenerative process affecting generations of learned generative models, in which the data they generate end up polluting the training set of the next generation. Being trained on polluted data, they then mis-perceive reality […] We separate two special cases: early model collapse and late model collapse. In early model collapse, the model begins losing information about the tails of the distribution; in late model collapse, the model converges to a distribution that carries little resemblance to the original one, often with substantially reduced variance.
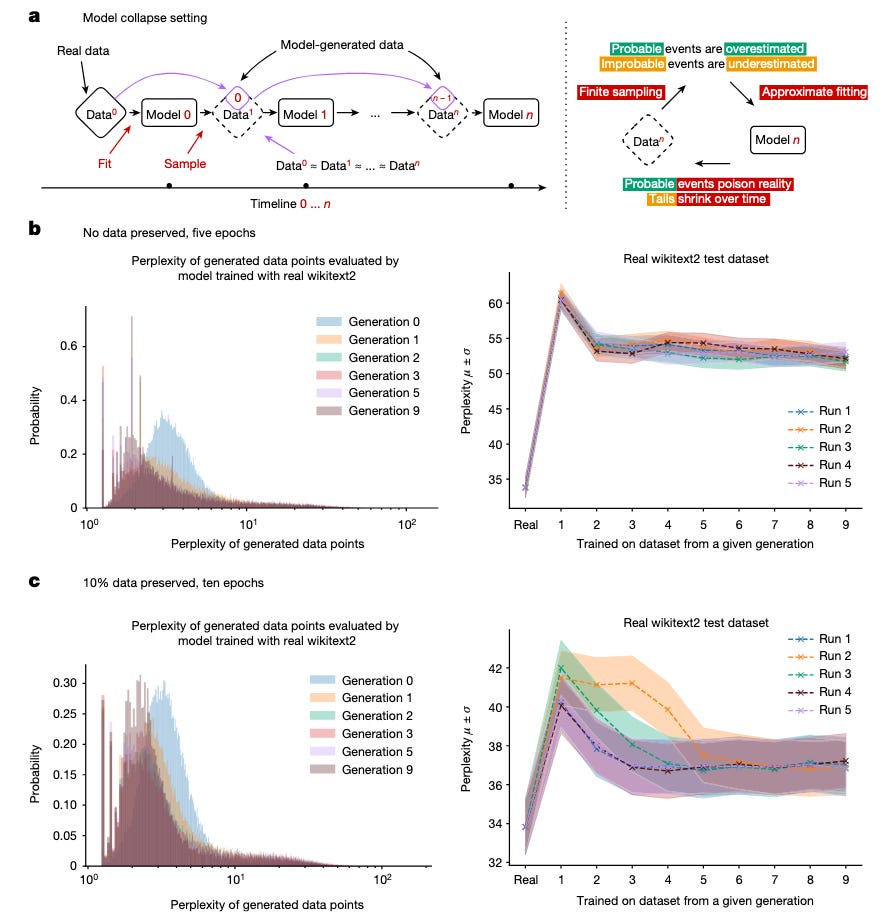
b,c, Performance of OPT-125m models of different generations evaluated using the original wikitext2 test dataset. Shown on the left are the histograms of perplexities of each individual data training sequence produced by different generations as evaluated by the very first model trained with the real data.

Perplexity is “one of the most common metrics for evaluating language models… can be thought of as an evaluation of the model’s ability to predict uniformly among the set of specified tokens in a corpus” (Hugging Face):

Initially I found perplexity as a single driving factor of model collapse potentially problematic, especially because
Model collapse is universal across various families of machine learning models. Yet, if small models such as GMMs and VAEs are normally trained from scratch, LLMs are different. They are so expensive to retrain from scratch that they are typically initialized with pre-trained models such as BERT, RoBERTa 5 or GPT-2
but perplexity definitionally “is not well defined for masked language models like BERT” (Hugging Face).
Then I realized that as model collapse is defined, this is an accurate measure. The main point of quantifying model collapse in this way is to measure prediction fairness: as the authors of the paper write,
What is different with the arrival of LLMs is the scale at which such poisoning can happen once it is automated. Preserving the ability of LLMs to model low-probability events [e.g. preserving tails and distribution of original data] is essential to the fairness of their predictions: such events are often relevant to marginalized groups. Low-probability events are also vital to understand complex systems. […]
To sustain learning over a long period of time, we need to make sure that access to the original data source is preserved and that further data not generated by LLMs remain available over time.
Situational Awareness: The Decade Ahead (Aschenbrenner, 2024)
If empirically-trained readers found the previous paper leaning a little too theoretical for their taste, they will find this essay even more challenging. At least, that was my first thought when I opened this essay by kid-genius-turned-Oxford-economics-researcher-turned-OpenAI-superalignment-researcher-turned-free-agent Leopold Aschenbrenner for the first time.
I found this Substack post by Dave Friedman that summarized my reactions to Aschenbrenner’s manifesto pretty perfectly:
Believing in the imminence of AGI, he notes, doesn’t require that we believe in sci-fi tropes. Rather we need only believe in the power of straight lines. […] His argument is rather straightforward: by looking at trends in (1) the amount of computational horsepower we can build with clusters of GPUs, (2) algorithmic improvements (“efficiencies” is the term he uses), and (3) “unhobbling,” by which he means “fixing obvious ways in which models are hobbled by default”, he concludes that the linear trend shown above will continue for the next several years, and that, by dint of this trend, AGI will be achieved rather rapidly.
The obvious counter to these arguments is this: we’re running out of data to train models on. If we can’t acquire more data to train more powerful LLMs on, then we can’t really progress much further than the state of the art.
[…] the entirety of Aschenbrenner’s argument in favor of rapid progress towards AGI depends crucially on AI research labs being able to solve the data constraint problem. In principle this should be a solveable problem—it’s not something which violates the laws of physics. But I’ve no idea about the prospects of solving it in the timeline he suggests. Maybe it’s doable, maybe it’s not. If it’s not, then the rest of his argument, insofar as it claims rapid progress to AGI, collapses.
Friedman outlines three approaches to tackle the data problem (my notes appended):
Synthetic data generation, “[relying] on the quality of the initial data and being able to generate realistic and diverse datasets” (which we are understanding the limitations of e.g. via the paper above)
Domain-specific data collection — some notable current players in the domain-specific data space being MIT and Scale; a commenter on Friedman’s post mentions “develop[ing] better and more efficient ways of ingesting data that [exist] outside the Internet”
Data efficiency improvements — figuring out how to use less data for equivalent training, which in addition / tandem to driving toward linear AGI also has environmental (e.g. carbon emissions) implications
Closing notes
There’s a fascinating dichotomy emerging in AI rhetoric: on one side, you have researchers pushing boundaries of intelligence and reasoning from a primarily “how high can we jump”-motivated standpoint; on the other side, you have those concerned with “how can we scale this / keep this sustainable and fair”. As with most things, to succeed in practice we need a healthy balance between the two. No doubt (as someone that has seen the challenges of trying to bridge gaps between theoreticians and practitioners firsthand in industry) it can be incredibly frustrating in the trenches, but I have faith that the best outcomes come from working conscientiously through friction in an environment centered around the same high-level goals. Transforming a unproductive dichotomy to a productive synergy is not a binary outcome and takes unwavering patience and active work (in many ways, exponentially harder with increase in media and industry attention bringing waves of new factors and chaos into systems).
So far I’m honestly delighted by the direction of research I am seeing. There is a refreshingly high level of focus on fairness and sustainability (both model development itself as well as the environmental and cost concerns around running these next-generation models at scale) in a field with no shortage of applications that have been correlated with and characterized by exorbitant wealth and excess. The cautious side of me can’t ignore the very real possibility of explosive growth leading to an imploding industry, but I am blessed to know and talk to AI researchers every day and I have never felt more confidence in the intelligence and ethics of the people driving this field forward.